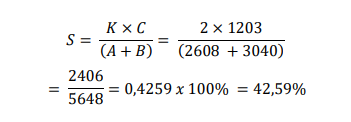Demo Program Rabin Karp Deteksi Plagiatisme Dokumen Pada Sistem Informasi Pendaftaran Proposal
30-Juni-2018 - Publish Admin
Algoritma Rabin-Karp diciptakan oleh Michael O. Rabin dan Richard M. Karp pada tahun 1987 yang menggunakan fungsi hashing untuk menemukan pattern di dalam string teks (Gipp, 2011). Algoortima Rabin-Karp (Gambar 2.1) digunakan sebagai algoritma deteksi kesamaan pada dokumen tugas akhir. Algoritma ini memiliki beberapa keunggulan dalam penerapannya, salah satunya adalah algoritma ini sangat cocok digunakan untuk string yang panjang.
Karakteristik algoritma Rabin-Karp, yaitu
Menggunakan sebuah fungsi hashing
Tahap prepocessing menggunakan kompleksitas waktu O(m)
Untuk tahap pencarian kompleksitasnya : O(mn)
Waktu yang diperlukan O(n+m)
Dalam algoritma Rabin-Karp, ada beberapa tahap yang harus dilelalui dalam implementasi algoritma tersebut.
Preprocessing
Tahap ini melakukan analisis semantik (kebenaran arti) dan sintaktik (kebenaran susunan) teks. Tujuan dari pemrosesan awal adalah untuk mempersiapkan teks menjadi data yang mengalami pengolahan lebih lanjut. Pembersihan yang dilakukan adalah pembersihan suatu teks dari karakter-karakter yang bersifat sebagai stoplist, dimana karakter tersebut banyak dan pasti muncul dalam setiap teks.
Rolling Hash
Fungsi yang digunakan untuk menghasilkan nilai hash dari rangkaian gram dalam algoritma Rabin-Karp adalah dengan menggunakan fungsi rolling hash.
bilangan prima adalah suatu bilangan asli yang lebih besar dari angka 1, faktor pembaginya adalah 1 dan bilangan itu sendiri. Angka 2 dan 3 adalah bilangan prima. Angka empat bukan bilangan prima. Sepuluh bilangan prima pertama adalah 2, 3, 5, 7, 11, 13, 17, 19, 23 dan 29.
N-grams adalah rangkaian terms dengan panjang N (Surahman, 2013). Kebanyakan yang digunakan sebagai terms adalah kata. N-grams merupakan sebuah metode yang diaplikasikan untuk pembangkitan kata atau karakter. Metode n-grams ini digunakan untuk mengambil potongan-potongan karakter huruf sejumlah n dari sebuah kata yang secara kontinuitas dibaca dari teks sumber hingga akhir dari dokumen.. Berikut ini adalah contoh n-grams dengan n=6:
Teks : proposal tugas akhir ilmu komputer
Hasil : {propos}{roposa}{oposal}{posal }{osal t}{sal tu}{al tug}
Metode hashing digunakan untuk mempercepat pencarian atau pencocokan suatu string. Apabila tidak di-hash, pencarian dilakukan karakter per karakter pada nama-namayang panjangnya bervariasi dan ada 26 kemungkinan pada setiap karakter. Namun pencarian menjadi lebih mangkus setelah di-hash karena hanya membandingkan beberapa digit angka dengan cuma 10 kemungkinan setiap angka. Nilai hash pada umumnya digambarkan sebagai fingerprint yaitu suatu string pendek yang terdiri atas huruf dan angka yang terlihat acak (data biner yang ditulis dalam heksadesimal). Contoh sederhana hashing adalah (Firdaus, 2008):
Firdaus, Hari
Munir, Rinaldi Rabin,
Michael
Karp, Richard
menjadi
7864 : Firdaus,Hari
9802 : Munir, Rinaldi
1990 : Rabin, Michae
8822 : Karp, Richard
Pencocokan
Pada processing, setiap m deret (kontigu) karakter pada field pencarian dicari hash key dengan cara yang sama dengan pencarian hash key untuk pattern. Perlu diingat dengan menggunakan aturan horner, pencarian untuk m deret karakter dapat dengan mudah dihitung dari m deret karakter predesesornya. Sedangkan untuk proses pencocokannya, dipakai sebuah teorema yaitu
Sebuah stringA identik dengan stringB, jika (syarat perlu) stringA memliki hash key yang sama dengan hash key yang dimiliki oleh stringB
Pengukuran Nilai Kemiripan
Mengukur similarity (kemiripan) dan jarak antara dua entitas informasi adalah syarat inti pada semua kasus penemuan informasi, seperti pada Information Retrieval dan Data Mining yang kemudian dikembangkan dalam bentuk perangkat lunak, salah satunya adalah sistem deteksi kesamaan (Salmusih, 2013). Penggunaan ukuran similarity yang tepat tidak hanya meningkatkan kualitas pilihan informasi tetapi juga membantu mengurangi waktu dan biaya proses sehingga mengperangkat lunakkan Dice's Similarity Coefficient dalam penghitungan nilai similarity yang menggunakan pendekatan kgram.
Dimana S adalah nilai similarity, A dan B adalah jumlah dari kumpulan n- grams dalam teks 1 dan teks 2. C adalah jumlah dari n-grams yang sama dari teks yang dibandingkan. Berikut adalah contoh dari penggunaan rumus tersebut. Terdapat dua buah dokumen teks (dok A dan dok B) dengan nilai n-gram masing- masing dokumen secara bertutur-turut adalah 2608 dan 3040, sedangkan nilai n-
gram yang sama adalah sebesar 1203. Maka hasil nilai dari kemiripan kedua dokumen tersebut adalah
 Shared
Shared
 Shared
Shared
 Shared
Shared
 Shared
Shared