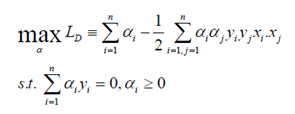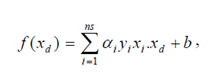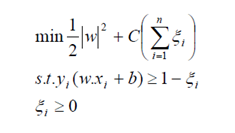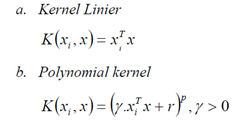Demo Program Implementasi Algoritma Support Verctor Machine (svm) Untuk Klasifikasi Nilai Tegangan Yang Dihasilkan Generator Pembangkit Listrik Pada Plta
10-Juni-2018 - Publish Admin
Dalam jurnal yang disusun oleh Pusphita, dkk (2014). Support Vector Machine(SVM) adalah suatu teknik untuk melakukan prediksi, baik dalam kasus klasifikasi maupun regresi. SVM memiliki prinsip dasar linier classifier yaitu kasus klasifikasi yang secara linier dapat dipisahkan, namun SVM telah dikembangkan agar dapat bekerja pada problem non-linier dengan memasukkan konsep kernel pada ruang kerja berdimensi tinggi. Pada ruang berdimensi tinggi, akan dicari hyperplane yang dapat memaksimalkan jarak (margin) antara kelas data.
Menurut Budi Santosa (2007) Support Vector Machine (SVM) adalah sistem pembelajaran yang menggunakan ruang hipotesis berupa fungsi-fungsi linier dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan learning bias yang berasal dari teori pembelajaran statistik.
Teori yang mendasari SVM sendiri sudah berkembang sejak 1960-an, tetapi baru diperkenalkan oleh Vapnik, Boser dan Guyon pada tahun 1992 dan sejak itu SVM berkembang dengan pesat. SVM adalah salah satu teknik yang relatif baru dibandingkan dengan teknik lain, tetapi memiliki performansi yang lebih baik di berbagai bidang aplikasi seperti bioinformatics, pengenalan tulisan tangan, klasifikasi teks dan lain sebagainya.
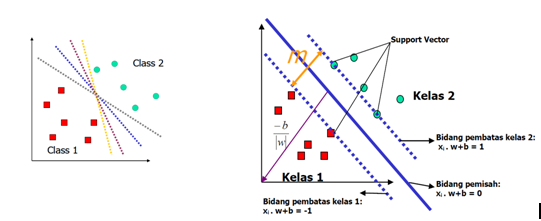
Linearly separable data merupakan data yang dapat dipisahkan secara linier. Misalkan adalah dataset dan yi∈{+1,−1} adalah label kelas dari data xi. Pada gambar 1 dapat dilihat berbagai alternatif bidang pemisah yang dapat memisahkan semua data set sesuai dengan kelasnya. Namun, bidang pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin paling besar.
Gambar 2. Alternatif bidang pemisah (kiri) dan bidang pemisah terbaik dengan margin (m) terbesar (kanan)
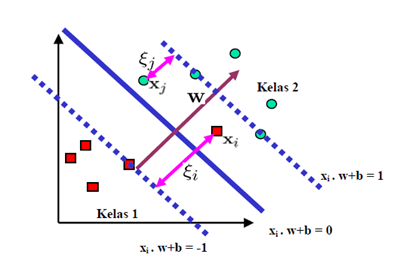
Adapun data yang berada pada bidang pembatas ini disebut support vector. Dalam contoh di atas, dua kelas dapat dipisahkan oleh sepasang bidang pembatas yang sejajar. Bidang pembatas pertama membatasi kelas pertama sedangkan bidang pembatas kedua membatasi kelas kedua, sehingga diperoleh:
xi.w+b ≥ +1 for yi = +1
xi.w+b ≥ +1 for yi = -1
w adalah normal bidang dan b adalah posisi bidang relatif terhadap pusat koordinat. Nilai margin (jarak) antara bidang pembatas (berdasarkan rumus jarak garis ke titik pusat) adalah . Nilai margin ini dimaksimalkan dengan tetap memenuhi (1). Dengan mengalikan b dan w dengan sebuah konstanta, akan dihasilkan nilai margin yang dikalikan dengan konstanta yang sama. Oleh karena itu, konstrain (1) merupakan scaling constraint yang dapat dipenuhi dengan rescaling b dan w . Selain itu, karena memaksimalkan sama dengan meminimumkan |w|2 dan jika kedua bidang pembatas pada (1) direpresentasikan dalam pertidaksamaan (2),
yi(xi.w + b)−1 ≥ 0
maka pencarian bidang pemisah terbaik dengan nilai margin terbesar dapat dirumuskan menjadi masalah optimasi konstrain, yaitu
s.t yi( xi .w + b) −1 ≥ 0
Persoalan ini akan lebih mudah diselesaikan jika diubah ke dalam formula lagrangian yang menggunakan lagrange multiplier. Dengan demikian permasalahan optimasi konstrain dapat diubah menjadi:
dengan tambahan konstrain, α ≥ 0i ( nilai dari koefisien lagrange). Dengan meminimumkan Lp terhadap w dan b, maka dari (w, b, α)= 0 diperoleh (5).
Vektor w sering kali bernilai besar (mungkin tak terhingga), tetapi nilai αi terhingga. Untuk itu, formula lagrangian Lp (primal problem) diubah kedalam dual problem LD. Dengan mensubsitusikan persamaan (6) ke LP diperoleh dual problem LD dengan konstrain berbeda.
. Jadi persoalan pencarian bidang pemisah terbaik dapat dirumuskan sebagai berikut:
Dengan demikian, dapat diperoleh nilai αi yang nantinya digunakan untuk menemukan w. Terdapat nilai αi untuk setiap data pelatihan. Data pelatihan yang memiliki nilai αi > 0 adalah support vector sedangkan sisanya memiliki nilai αi =1. Dengan demikian fungsi keputusan yang dihasilkan hanya dipengaruhi oleh support vector.
Formula pencarian bidang pemisah terbaik ini adalah pemasalahan quadratic programming, sehingga nilai maksimum global dari i α selalu dapat ditemukan. Setelah solusi pemasalahan quadratic programming ditemukan (nilai αi), maka kelas dari data pengujian x dapat ditentukan berdasarkan nilai dari fungsi keputusan:
xi adalah support vector, ns = jumlah support vector dan dx adalah data yang akan diklasifikasikan. Untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier formula SVM harus dimodifikasi karena tidak akan ada solusi yang ditemukan. Oleh karena itu, kedua bidang pembatas (1) harus diubah sehingga lebih fleksibel (untuk kondisi tertentu) dengan penambahan variabel ξi (ξi ≥ 0, i : ξi = 0. Pencarian bidang pemisah terbaik dengan dengan penambahan variabel ξi sering juga disebut soft margin hyperplane.
Dengan demikian formula pencarian bidang pemisah terbaik berubah menjadi:
Gambar 3. Soft margin hyperplane
Pengubahan Lp ke dalam dual problem, menghasilkan formula yang sama dengan persamaan (6) sehingga pencarian bidang pemisah terbaik dilakukan dengan cara yang hampir sama dengan kasus dimana data dapat dipisahkan secara linier, tetapi rentang nilai αi adalah 0 ≥αi≥ C . Instance yang memiliki nilai C =αi disebut bounded support vector.
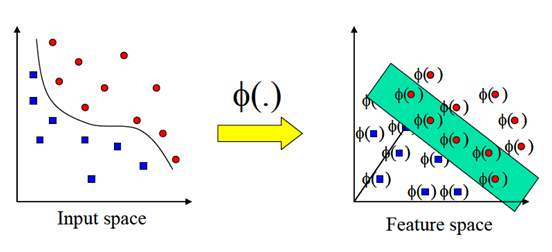
Metode lain untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier adalah dengan mentransformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space.
Gambar 4. Transformasi dari vektor input ke feature space
Syarat sebuah fungsi untuk menjadi fungsi kernel adalah memenuhi teorema Mercer yang menyatakan bahwa matriks kernel yang dihasilkan harus bersifat positive semi definite. Fungsi kernel yang umum digunakan adalah sebagai berikut:
Fungsi kernel yang direkomendasikan untuk diuji pertama kali adalah fungsi kernel RBF karena memiliki performansi yang sama dengan kernel linier pada parameter tertentu, memiliki perilaku seperti fungsi kenel sigmoid dengan parameter tentu dan rentang nilainya kecil.
 Shared
Shared
 Shared
Shared
 Shared
Shared
 Shared
Shared
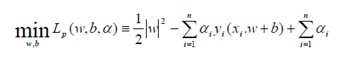

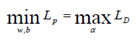 . Jadi persoalan pencarian bidang pemisah terbaik dapat dirumuskan sebagai berikut:
. Jadi persoalan pencarian bidang pemisah terbaik dapat dirumuskan sebagai berikut: