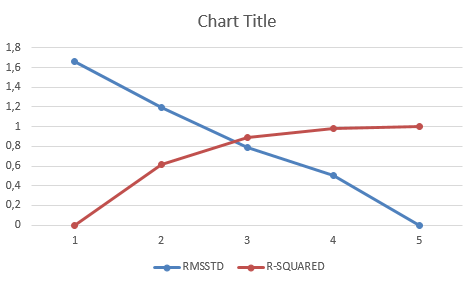
Shared
Shared
 Shared
Shared
 Shared
Shared
 Shared
Shared

Demo Program Neural Network Backpropagation Deteksi Tulisan Korea
POST: ADMIN
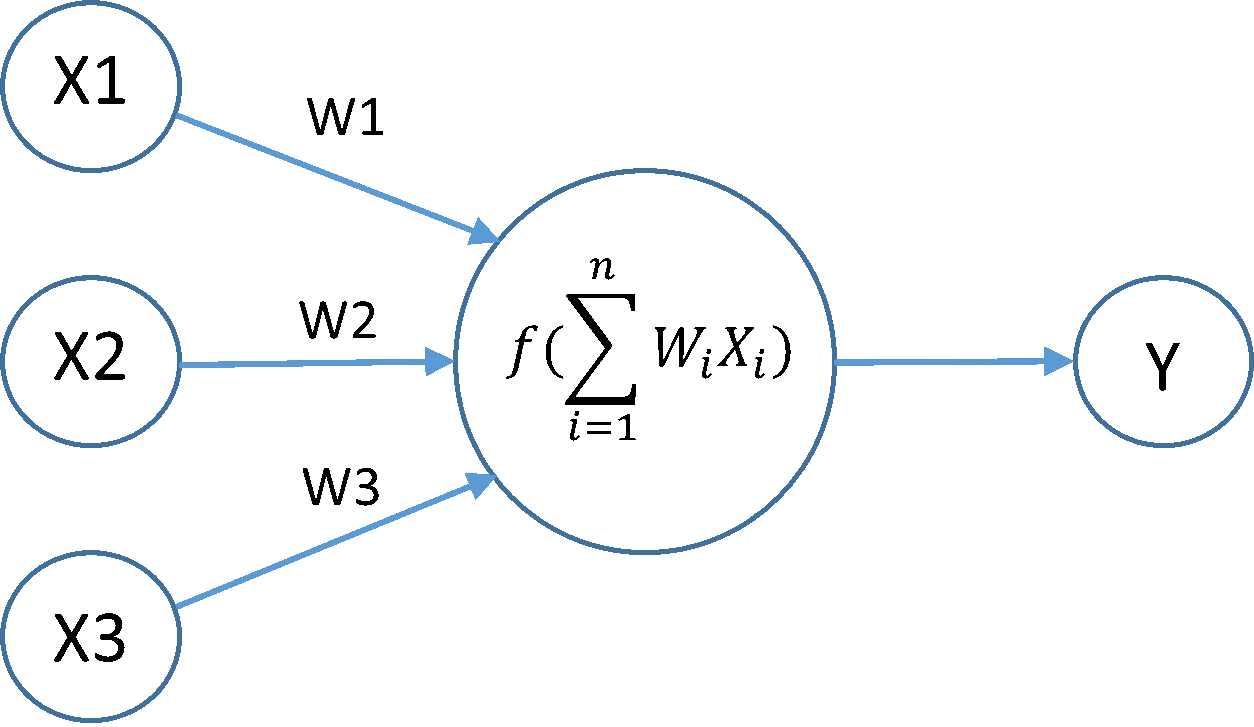
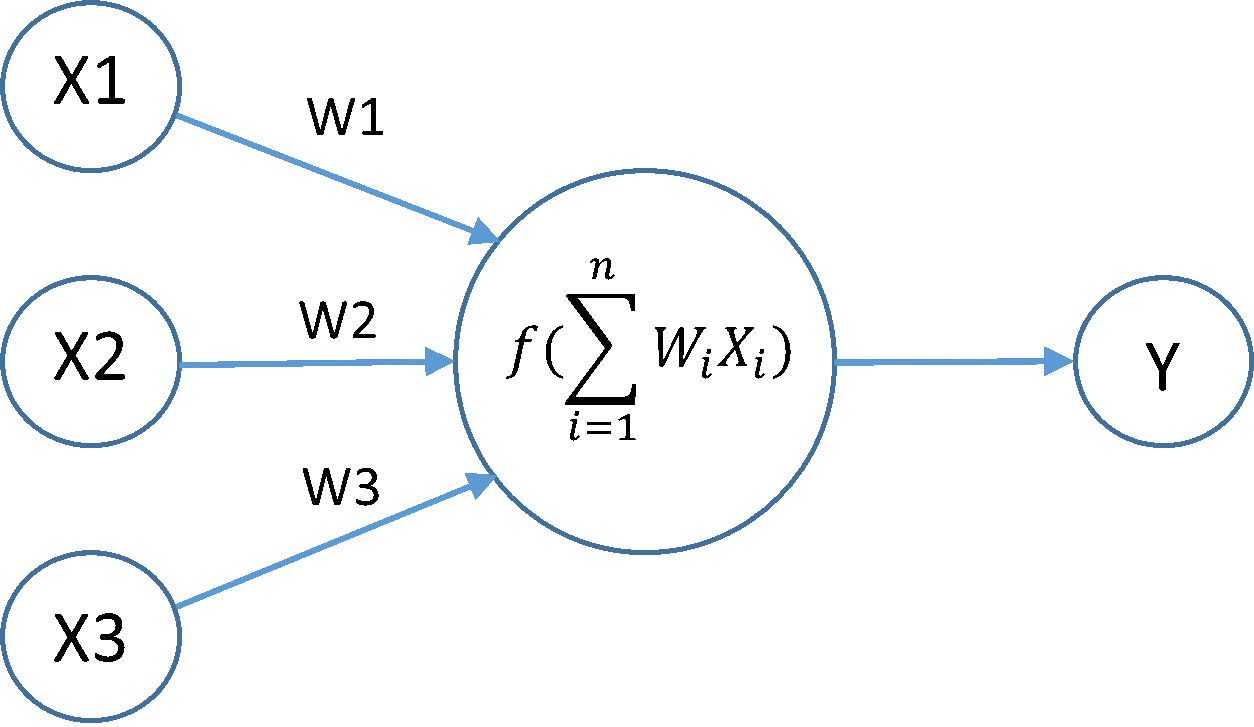
DEMO PROGRAM NEURAL NETWORK BACKPROPAGATION DETEKSI TULISAN KOREA 27-JUNI-2018 - PUBLISH ADMIN algoritma backpropagation Demo Program Backpropagation adalah suatu metode yang paling umum untuk digunakan sebagai pelatihan jaringan saraf tiruan (JST). atau juga disebut simulated neural network (SNN), atau umumnya hanya disebut neural network (NN)). neural network (NN) itu sendiri adalah merupakan sebuah sistem pembelajaran terhadap penerimaan informasi yang memiliki kinerja layaknya sebuah jaringan syaraf pada manusia. NN diimplementasikan dengan menggunakan program komputer sehingga mampu menyelesaikan sejumlah proses perhitungan. Salah satu penggunaan NN adalah untuk pengenalan pola. Sistem pengenalan pola merupakan komponen penting dalam proses peniruan cara kerja sistem manusia Sejarah Backpropagation Metode Backpropagation ini pertama kali diperkenalkan oleh Paul Werbos pada tahun1974, kemudian dikemukakan kembali oleh David Parker di tahun 1982 dan kemudian dipopulerkan oleh Rumelhart dan McCelland pada tahun 1986. Pada Algoritma BackPropagationini, arsitektur jaringan menggunakan jaringan banyak lapis. Secara garis besar proses pelatihan pada jaringan saraf tiruan dikenal beberapa tipe pelatihan, yaitu : Supervised Training Unsupervised Training Fixed-Weight Nets.
Demo Program Pengolahan Citra Digital Edge Detection Filtering
POST: ADMIN
DEMO PROGRAM PENGOLAHAN CITRA DIGITAL EDGE DETECTION FILTERING 25-Juni-2018 - Publish Admin TEKNIK MENDETEKSI TEPI(Tanpa Konvolusi) ? Homogeneity Operator (Operator homogenitas) ? Menghitung selisih titik yang dicari dengan titik disekitarnya. Dari selisih tersebut dicari nilai absolut paling besar dan hasilnya digunakan untuk mengganti nilai titik tengah yang dihitung. pengolahan citra TEKNIK MENDETEKSI TEPI(Tanpa Konvolusi) ? Operator homogenitas ? Output dari operator homogenitas : ? Nilai terbesar dari harga mutlak 8 selisih
Demo Program Multy Layer Perceptron Dalam Menentukan Kompeten Siswa
POST: ADMIN
DEMO PROGRAM MULTY LAYER PERCEPTRON DALAM MENENTUKAN KOMPETEN SISWA 25-JUNI-2018 - PUBLISH ADMIN algoritma neural network Training Data No Input 1 Input 2 Output 1 0 0 0 2 0 1 0 3 1 0 0 4 1 1 1 Perhitungan : Data ke 1 Pada perhitungan ini kita memberikan nilai bias pada masing-masing data yaitu -1, sehingga jika dilihat dalam bentuk table menjadi seperti: No Bias Input 1 Input 2 Output 1 -1 0 0 0 Selanjutnya karena data ke 1 adalah data awal maka pada perhitungan data pertama ini kita harus memberikan nilai bobot terlebih dahulu, nilai bobot ini berupa random. Disini saya berikan nilai bobot untuk data pertama yaitu: W0 = 0,3 , w1 = 0,5 dan w2 = -0,4 Kemudian jika dilihat dalam bentuk table maka hasilnya akan menjadi seperti : No Bias Input 1 Input 2 Output W0 W1 W2 1 -1 0 0 0 0,3 0,5 -0,4 Kemudian mengitung net dengan persamaan: NET=Y_IN= b + ?xi Wi NET=Y_IN= ((-1*0,3)+ (0*0,5)+(0*-0,4)*1000)/1000 NET = -0,3 Maka No Bias Input 1 Input 2 Output W0 W1 W2 NET(SUM) 1 -1 0 0 0 0,3 0,5 -0,4 -0,3 Selanjutnya membentuk aktivasi (Y) Syarat: Jika nilai net(sum) besar dari nol(0) maka nilai aktivasinya yaitu 1 Jika nilai net (sum) kecil dari nol(0) maka nilai aktivasinya yaitu 0 Nilai NET = -0,3 Y = 0, jika dilihat dalam bentuk table No Bias Input 1 Input 2 Output W0 W1 W2 NET(SUM) aktivasi 1 -1 0 0 0 0,3 0,5 -0,4 -0,3 0 Selanjutnya mencari nilai ERROR Error = ouput – aktivasi Error = 0 No Bias Input 1 Input 2 Output W0 W1 W2 NET(SUM) aktivasi Error 1 -1 0 0 0 0,3 0,5 -0,4 -0,3 0 0 Data ke 2 No Bias Input 1 Input 2 Output 2 -1 0 1 0 Pencarian bobot pada data ke dua dengan persamaan: multilayer perceptron W0 = nilai bobot sebelumnya + learning rate x input sebelumnya x error sebelumya Penjelasan Learning rate = 0,1 maka W0 = 0,3+0,1x-1x0 W0 = 0,3 W1 = 0,5+0,1x0x0 W1 = 0,5 W2 = -0,4+0,1x0x0 W2 = -0,4 Sehingga dalam bentuk table No Bias Input 1 Input 2 Output W0 W1 W2 2 -1 0 1 0 0,3 0,5 -0,4 Kemudian mengitung net dengan persamaan: NET=Y_IN= b + ?xi Wi NET=Y_IN= ((-1*0,3)+ (0*0,5)+(1*-0,4)*1000)/1000 NET = -0,7 Maka No Bias Input 1 Input 2 Output W0 W1 W2 NET(SUM) 2 -1 0 1 0 0,3 0,5 -0,4 -0,7 Selanjutnya membentuk aktivasi (Y) Syarat: Jika nilai net(sum) besar dari nol(0) maka nilai aktivasinya yaitu 1 Jika nilai net (sum) kecil dari nol(0) maka nilai aktivasinya yaitu 0 Nilai NET = -0,7 Y = 0, jika dilihat dalam bentuk table No Bias Input 1 Input 2 Output W0 W1 W2 NET(SUM) aktivasi 2 -1 0 1 0 0,3 0,5 -0,4 -0,7 0 Selanjutnya mencari nilai ERROR Error = ouput – aktivasi Error = 0 No Bias Input 1 Input 2 Output W0 W1 W2 NET(SUM) aktivasi Error 2 -1 0 0 0 0,3 0,5 -0,4 -0,7 0 0 Kemudian ulang kembali proses diatas sampai data ke 4, selanjutnya hitung nilai error. Jika total nilai error dari data ke 1 sampai data ke 4 = 0 maka pembentukan jaringan di hentikan jika lebih dari 0 maka proses pencarian akan terus berlangsung, ulangi seperti langkah-langkah diatas sampai total nilai error bernilai nol (0).
Demo Program Metode Fuzzy C Means Penentuan Penerimaan Bantuan Rumah Tidak Layak Huni
POST: ADMIN
DEMO PROGRAM METODE FUZZY C MEANS PENENTUAN PENERIMAAN BANTUAN RUMAH TIDAK LAYAK HUNI 13-JUNI-2018 - PUBLISH ADMIN Konsep dasar FCM yaitu menentukan pusat cluster, yang akan menandai lokasi rata-rata untuk setiap cluster. Dengan cara memperbaiki pusat cluster dan derajat keanggotaan setiap titik data secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak smenuju lokasi yang tepat. Perulangan ini didasarkan pada minimisasi fungsi obyektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut. Demo Program Output dari FCM bukan merupakan fuzzy inference system, namun merupakan deretan pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data. Informasi ini dapat digunakan untuk membangun suatu fuzzy inference system. Mekanisme Fuzzy C-Means Clustering Menentukan: Matriks X yang merupakan data yang akan dicluster, berukuran k x j, dengan k = jumlah data yang akan di-cluster dan j = jumlah variabel/atribut (kriteria).
Demo Program Algoritma Saw Penentuan Pembagunan Lokasi Perumahan Dengan Gis
POST: ADMIN
DEMO PROGRAM ALGORITMA SAW PENENTUAN PEMBAGUNAN LOKASI PERUMAHAN DENGAN GIS 13-JUNI-2018 - PUBLISH ADMIN Metode SAW merupakan metode yang juga dikenal dengan metode penjumlahan berbobot. Konsep dasar metode saw adalah mencari penjumlahan terbobot dari rating kinerja pada setiap alternatif pada semua atribut (Fishburn, 1967) (MacCrimmon, 1968). Metode SAW membutuhkan proses normalisasi matriks keputusan (X) ke suatu skala yang dapat diperbandingkan dengan semua rating alternatif yang ada. Metode ini merupakan metode yang paling terkenal dan paling banyak digunakan dalam menghadapi situasi Multiple Attribute Decision Making (MADM). MADM itu sendiri merupakan suatu metode yang digunakan untuk mencari alternatif optimal dari sejumlah alternatif dengan kriteria tertentu. ada beberapa tahapan untuk menyelesaikan suatu kasus menggunakan metode SAW. Demo Program Menentukan kriteria-kriteria yang akan dijadikan acuan dalam pengambilan keputusan, yaitu Ci. Menentukan rating kecocokan setiap alternatif pada setiap kriteria. Membuat matriks keputusan berdasarkan kriteria(Ci), kemudian melakukan normalisasi matriks berdasarkan persamaan yang disesuaikan dengan jenis atribut (atribut keuntungan ataupun atribut biaya) sehingga diperoleh matriks ternormalisasi R. Hasil akhir diperoleh dari proses perankingan yaitu penjumlahan dari perkalian matriks ternormalisasi R dengan vektor bobot sehingga diperoleh nilai terbesar yang dipilih sebagai alternatif terbaik (Ai) sebagai solusi. Perhitungan Manual Seperti yang telah diuraikan sebelumnya tentang penerapan metode SAW(Simple Additive Weighting) dengan contoh perhitungan manual sebagai berikut. Bobot Kriteria
Demo Program Survei Crowdsourcing Berbasis Web Dengan Weighted Majority Voting Untuk Mengetahui Posisi Dosen
POST: ADMIN
SURVEI CROWDSOURCING BERBASIS WEB DENGAN WEIGHTED MAJORITY VOTING UNTUK MENGETAHUI POSISI DOSEN DEMO PROGRAM 11-JUNI-2018 - PUBLISH ADMIN Majority Voting adalah metode sederhana yang menggunakan konsep pengambilan keputusan hasil vote yang diperoleh dari jumlah terbesar dari masing-masing pilihan vote yang ada. Metode Majority Voting ini memiliki kelemahan pada kondisi jumlah suara mayoritas lebih dari satu. Perbaikan dari metode Majority Voting adalah Weighted Majority Voting, setiap suara diberi bobot, kemudian seluruh bobot dijumlahkan dan hasil akhir labelnya ditentukan dari rentang nilai jumlah bobot tersebut. Berbeda dengan majority voting biasa, setiap hasil voting dari pakar ditotalkan dengan bobot yang berbeda, di mana 0 ? ? ? 1 (? = 1, ..., n). Akan sangat baik apabila pengambilan keputusan akhir didasarkan pada nilai pilihan yang paling banyak dan bobot yang paling besar karena pada setiap prediksi akan terlihat mana pakar yang lebih baik dari yang lainnya. Intinya adalah, setiap pakar yang melakukan kesalahan bobotnya dikurangi 1/2 dari awalnya 1 menjadi ½, ¼, 1/8, dan seterusnya. Dalam penelitian ini, setiap user yang terdaftar dalam aplikasi awalnya memiliki bobot suara 1. Satu kali putaran voting adalah 1 jam, jadi setiap menit ke 59.00 akan berjalan sebuah query untuk menghitung bobot dan mengupdate hasil voting posisi terkini dosen, dan saat itu pula pilihan mayoritas dan minoritas dibandingkan. Beberapa user yang memilih pilihan minoritas, maka bobotnya akan dikurangi setengah dan begitu seterusnya.
Demo Program Rancang Bangun Aplikasi Kecerdasan Majemuk Anak Dengan Metode Indikator The Roger
POST: ADMIN
RANCANG BANGUN APLIKASI KECERDASAN MAJEMUK ANAK DENGAN METODE INDIKATOR THE ROGER DEMO PROGRAM 10-JUNI-2018 - PUBLISH ADMIN Rogers Indikator Multiple Intelligences yang dikembangkan oleh J.Keith Rogers pada tahun 2011, yang digunakan untuk memeriksa valid atau tidaknya yang terkait dengan kriteria. Untuk menanggapi pernyataan yang diberikan menggunakan lima skala penilaian, yaitu tidak pernah, jarang, kadang-kadang, sering, dan selalu. Demo Program Rogers Indikator Multiple Intelligences (RIMI) terdapat 56 item soal yang didasarkan pada 8 kriteria Multiple Intelligences yang dijelaskan dalam (Gardner, 1983) Frames of Mind: The Theory of Multiple Intelligences. Anak yang didampingi orangtua, kemudian dapat mengisi pertanyaan yang tersedia sesuai dengan kriteria kecerdasan majemuk. Contoh Tes Indikator Kecerdasan Majemuk Rogers Petunjuk: Berilah tanda check (V) pada skor yang sesuai dengan diri anda
Demo Program Implementasi Algoritma Support Verctor Machine (svm) Untuk Klasifikasi Nilai Tegangan Yang Dihasilkan Generator Pembangkit Listrik Pada Plta
POST: ADMIN
IMPLEMENTASI ALGORITMA SUPPORT VERCTOR MACHINE (SVM) UNTUK KLASIFIKASI NILAI TEGANGAN YANG DIHASILKAN GENERATOR PEMBANGKIT LISTRIK PADA PLTA DEMO PROGRAM 10-JUNI-2018 - PUBLISH ADMIN Dalam jurnal yang disusun oleh Pusphita, dkk (2014). Support Vector Machine (SVM) adalah suatu teknik untuk melakukan prediksi, baik dalam kasus klasifikasi maupun regresi. SVM memiliki prinsip dasar linier classifier yaitu kasus klasifikasi yang secara linier dapat dipisahkan, namun SVM telah dikembangkan agar dapat bekerja pada problem non-linier dengan memasukkan konsep kernel pada ruang kerja berdimensi tinggi. Pada ruang berdimensi tinggi, akan dicari hyperplane yang dapat memaksimalkan jarak (margin) antara kelas data. Demo Program Menurut Budi Santosa (2007) Support Vector Machine (SVM) adalah sistem pembelajaran yang menggunakan ruang hipotesis berupa fungsi-fungsi linier dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan learning bias yang berasal dari teori pembelajaran statistik. Teori yang mendasari SVM sendiri sudah berkembang sejak 1960-an, tetapi baru diperkenalkan oleh Vapnik, Boser dan Guyon pada tahun 1992 dan sejak itu SVM berkembang dengan pesat. SVM adalah salah satu teknik yang relatif baru dibandingkan dengan teknik lain, tetapi memiliki performansi yang lebih baik di berbagai bidang aplikasi seperti bioinformatics, pengenalan tulisan tangan, klasifikasi teks dan lain sebagainya. Linearly separable data merupakan data yang dapat dipisahkan secara linier. Misalkan adalah dataset dan yi ?{+1,?1} adalah label kelas dari data xi. Pada gambar 1 dapat dilihat berbagai alternatif bidang pemisah yang dapat memisahkan semua data set sesuai dengan kelasnya. Namun, bidang pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin paling besar.
Demo Program Implementasi Algoritma Rock(robust Clustering Using Links) Untuk Menentukan Pola Cluster Pelanggaran Lalu Lintas
POST: ADMIN
IMPLEMENTASI ALGORITMA ROCK(ROBUST CLUSTERING USING LINKS) UNTUK MENENTUKAN POLA CLUSTER PELANGGARAN LALU LINTAS DEMO PROGRAM 10-JUNI-2018 - PUBLISH ADMIN Algoritma ROCK merupakan suatu algoritma clustering yang mengelompokkan data berbasiskan LINK antar data yang ada. ROCK sendiri adalah singkatan dari RObust Clustering using links. Data yang mempunyai tingkat hubungan (link) tinggi akan digabungkan ke dalam satu cluster, sedang yang mempunyai tingkat hubungan (link) yang kecil akan dipisahkan dari cluster dimana data tersebut dikelompokkan. Lihat Demo Program Contoh Perhitungan Manual Algoritma ROCK Mengiput nilai k dan ? Misalnya menginputkan nilai k = 3 dan ? = 0,6 2. Menghitung nilai similaritas antara suatu klaster dengan klaster lainnya, menggunakan rumus jaccard coefficient Contoh Perhitungan Manual : Kecamatan Jenis Kelamin Usia Pekerjaan Pasal & Ancaman Sanksi 6 7 9 13 20 1 7 9 15 20 6 7 9 14 20 6 7 9 14 20 1 7 9 14 20 P dalam rumus maksudnya baris. P = irisan (banyaknya nilai yang sama) dibagi gabungan (banyak nilai yang sama dihitung 1 + banyak nilai yang berbeda) Jadi : nilai sim p1,p2 = 3/7 = 0,248 nilai sim p1,p3 = 4/6 = 0,667 nilai sim p1,p4 = 4/6 = 0,667 nilai sim p1,p5 = 3/7 = 0,248 nilai sim p2,p3 = 3/7 = 0,248 nilai sim p2,p4 = 3/7 = 0,248 nilai sim p2,p5 = 4/6 = 0,667 nilai sim p3,p4 = 5/5 = 1 nilai sim p3,p5 = 4/6 = 0,667 nilai sim p4,p5 = 4/6 = 0,667 nilai sim p5, p5 = 1 (mencari similaritas p itu sendiri = 1 ) bisa juga dilihat di jurnal “Algoritma Rock” halaman 39 – 45 contoh perhitungan algoritma rock.. dibikin matriks 3. Menentukan nilai matrik tetangga (neighbors) A dengan menggunakan nilai-nilai ambang (?). Dengan ? = 0,6 maka cari nilai tetangga antara p1, p2, p3, p4, p5 yang nilai similaritasnya diatas/ lebih besar dari nilai ? maka didapatkan : Antara garis merah yang merupakan p1 terdapat nilai similaritas yang lebih besar dari nilai ? Garis biru merupakan nilai similaritas yang lebih besar dari nilai ?